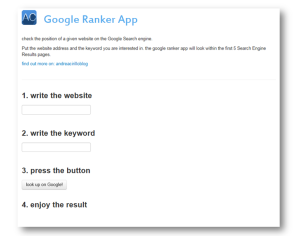
If you have a blog you may want to discover how your website is performing for given keywords on Google Search Engine. As we all know, this topic is not a trivial one.
Problem is that the analogycal solution would be quite time-consuming, requiring you to search your website for every single keyword, on many many pages.
Feeling this way?
[caption id=“attachment_273” align=“aligncenter” width=“300”] “Pain and fear, pain and fear for me” - Oliver Twist[/caption]
“Pain and fear, pain and fear for me” - Oliver Twist[/caption]
I was.
Therefore, I have started developing a lean Shiny app, the Google Ranker App that simply asks you for the website and the keyword, carrying on all the rest.
Algorithm specs
If you are not interested in programming stuff, you can skip straight forward this paragraph.
As all the Shiny Apps , the Google_ranker_app is based on R language.
You can download the whole reproducible R Studio Project using the button at the end of the post, but I would like to strikeout some of the algorithm components, giving a look to some details and the to the big picture:

querying google via URL
the queryng job is done leveraging the getForm() function in the RCurl package:
[code language=“r”] web_page = getForm(“http://www.google.com/search", hl=“en”, lr=“”, ie=“ISO-8859-1”, q=gsub(” “,”+“,keyword), btnG=“Search”,start=i) [/code]
As you can see, querying Google using the URL lets you specify all the search parameters, and this is quite an useful feature. Altough I haven’t found an official Google guide ( please let me know if I am missing it), there are quite a lot of posts regarding the topic. I personally reccomend you the one from Search Engine Land, for its completness and clarity.
After obtaining the resulting Search Engine Result Page (SERP) and assigning it to web_page, you need to parse it to a list object, in order to make it readable. This is easily obtained through the htmlTreeParse() function
[code language=“r”] web_page = htmlTreeParse(web_page) [/code]

handling error 302
When I started developing the Google Ranker App, one of the first obstacles was the error 302: “the document has moved to…[link]“. The error was a message returned by google when I make some subsequent repetion of the query.
Again, no official guide from Google is provided, but the error seems to be something related to repetitive query from the same IP, that let Google think you are some kind of robot.
In order to detect the occurence of this error, I used the grepl() function
[code language=“r”] if (grepl(“302 Moved”,(web_page[3]))==TRUE){ scan_result[(i/10)+1] = 200} [/code]
the grepl() function, from R base package, return a boolean value after looking for a pattern in a string.
I used this function to look for “302 Moved” pattern in order to intercept the mentioned error, and distinguish it from the absence of the website on the SERP page. As you can see, in case the pattern is present, the scan_result object, at [(i/10)+1] index assume value 200. We will look to the purpose of scan_result later, at crafting an user-friendly output paragraph.

evaluating the presence of the given website
in order to evaluate the presence of the given website in the SERP, we use the grep() function, similar to the grepl() function but designed to obtain the matching index of the given pattern in the given string.
[code language=“r”] else if (sum((grep(website,web_page))>0)){ scan_result[(i/10)+1]= (i/10)+1 rm(web_page) } else {scan_result[(i/10)+1] = 100 #just to make the min() function work rm(web_page)}} [/code]
in case of match, the mentioned scan_result object , at the mentioned index, will assume value [(i/10)+1], in case of none-match it will assume value 100. Just look to the next paragph to see the reason why.

Making things stick togheter: the serp_scanner function
All of the code chunks reproduced togheter are included in a custom function: the serp_scanner() function:
[code language=“r”] serp_scanner = function(keyword,website){ scan_result = rep(0,5) #initialize the scan_result vector for (i in seq(from=0,to=40,by=10)){ #grab the SERP page web_page = getForm(“http://www.google.com/search", hl=“en”, lr=“”, ie=“ISO-8859-1”, q=gsub(” “,”+“,keyword), btnG=“Search”,start=i) #make it readable web_page = htmlTreeParse(web_page) if (grepl(“302 Moved”,(web_page[3]))==TRUE){ scan_result[(i/10)+1] = 200}#error 302 else if (sum((grep(website,web_page))>0)){ scan_result[(i/10)+1]= (i/10)+1 #website found rm(web_page) } else {scan_result[(i/10)+1] = 100 #website not found rm(web_page)}} return(scan_result)} [/code]
this function contains a loop made of 5 cycles (i in seq(from=0,to=40,by=10)) that makes the Google Ranker App go through the first 5 SERP for the given keyword, looking for the given website. the result of each cycle is assigned to the scan_result object, a vector of length 5:
positive result (website found) the scan_result will assume, at the given index, a number equal to the number of the page (1 of 10, 2 of 10 etc.)
negative result (website not found) the scan_result will assume value 100
error 302 (See above) the scan_result will assume value 200
we are going to look to the reason why of those two last cases in the next paragraph.

{kind=link}
Crafting an user friendly output.
The result you see at point 4 in the Google Ranker App user interface, is crafted starting from the serp_scanner() result, for the website and keyword given by the user ( points 1 and 2). More precisely, the App looks for the minimum in the scan_result vector:
in case of positive result it will be a number from 1 to 5 representing the number of the SERP.
in case of negative result ( website not present from 1 to 5 SERP), the number will be 100, and this will let the app understand the website is not present.
in case of Google giving error 302, the minimum will be 200, and this will be easily intercepted from the app.
An if statement does all the job, pasting a different string for the different cases:
[code language=“r”] output$rank_1 = renderText({ result=serp_scanner(input$selected_keyword_1,website()) if (website()==“”|input$selected_keyword_1==“”){“”} else{if (min(result)==200){“google is thinking we are robots (error 302)! please try later”} else if(min( result) ==100){“the selected website doesn’t appear within the first 5 SERP pages”} else{ paste(“the website appears on SERP page n”,min( result),“for the given keyword”, sep=” “)} } }) [/code]
What (could be) next
Currently working on those possible development:
in-page ranking detection through html analysis.
thanks to the htmlTreeParse it is quite easy to look inside the html script and define the relative position for the website, ** **
possibility to define some query parameters
like language or local search. This can be obtained thanks to the pecularity of getForm function, that takes care of bringing the parameters together and constructing the full URI name.
multiple keywords allowance
self-explaining, am I right?
In order to obtain full understanding of the code you can download (for free) the whole R Studio project using the button below.
If you found the Google Ranker App useful, you may be interested in other Shiny Apps I developed for analytics and productivity purposes. Find them out at software page
download the R studio project of Google Ranker App
Icons made by Google from www.flaticon.com is licensed under CC BY 3.0